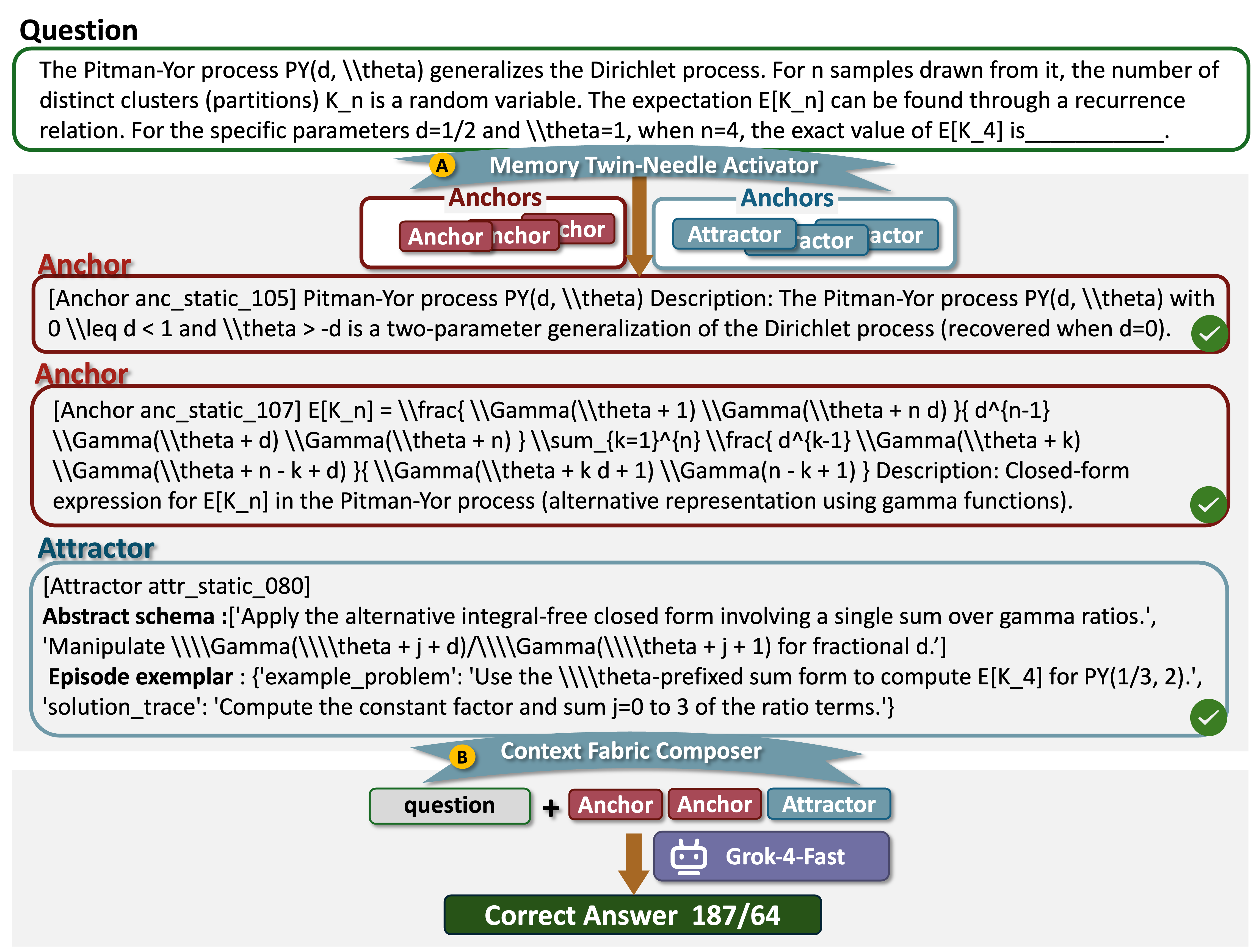
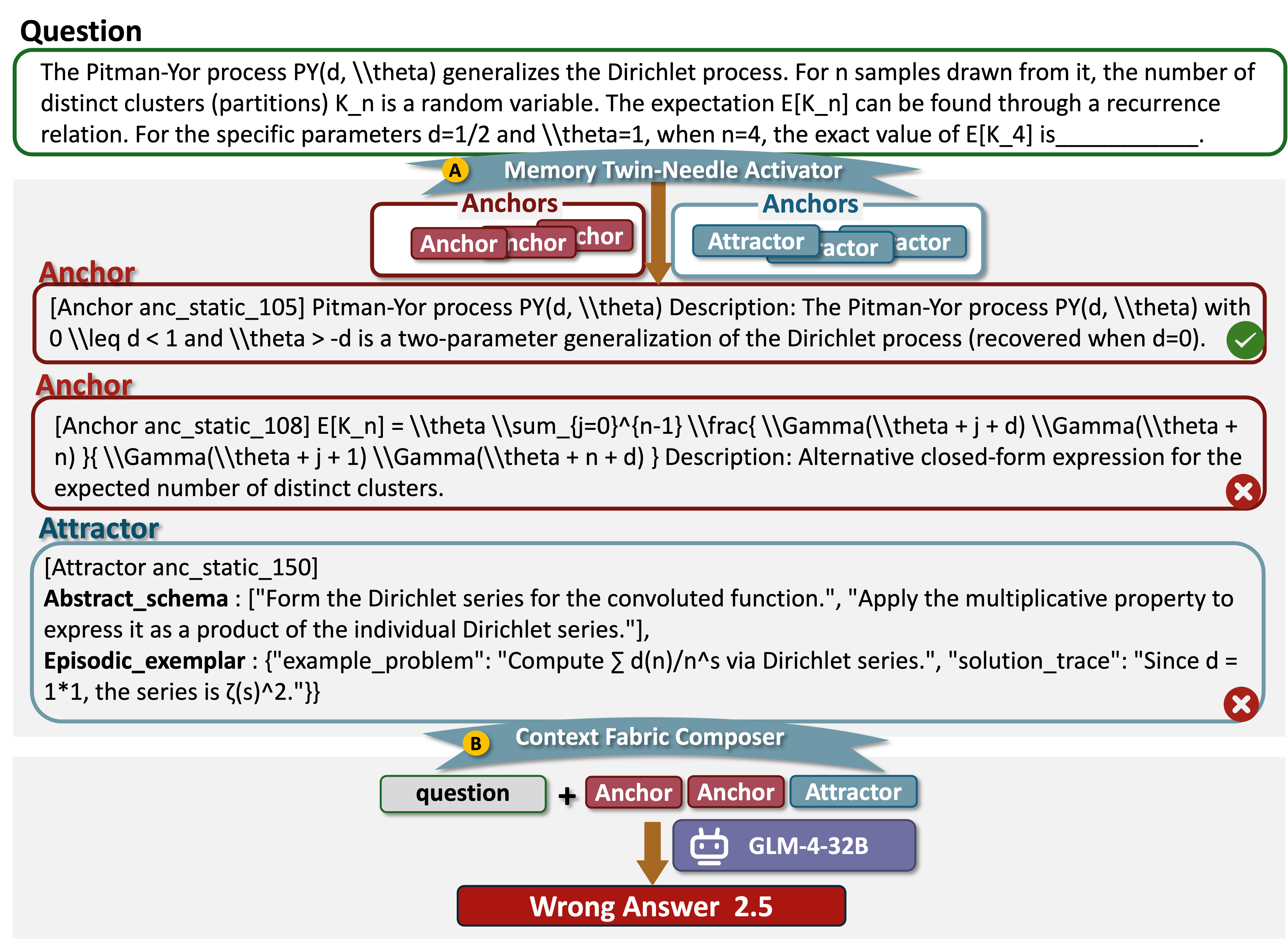
A3-Bench
A3-Bench
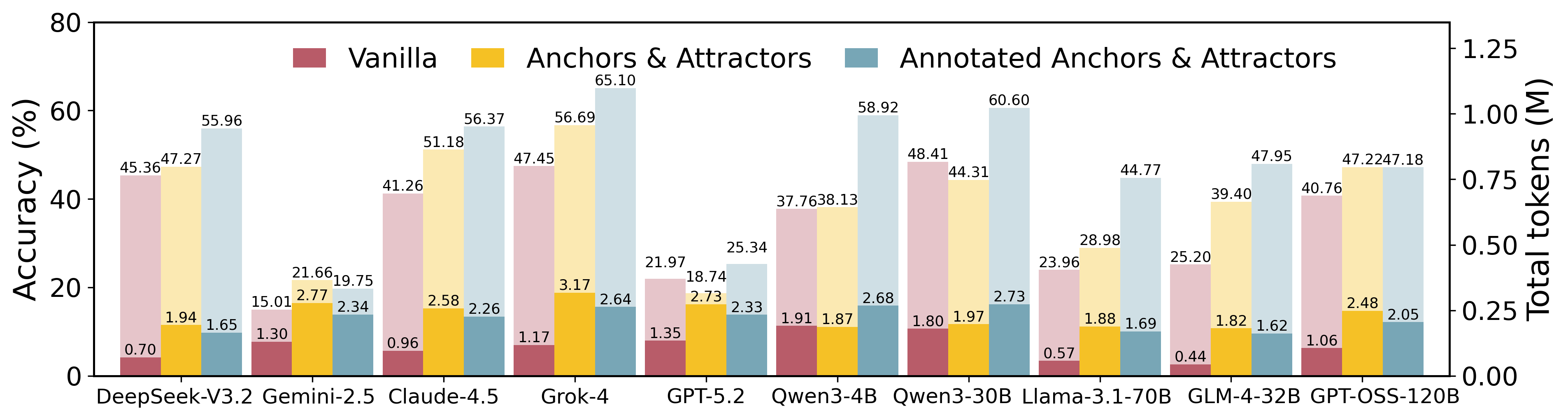
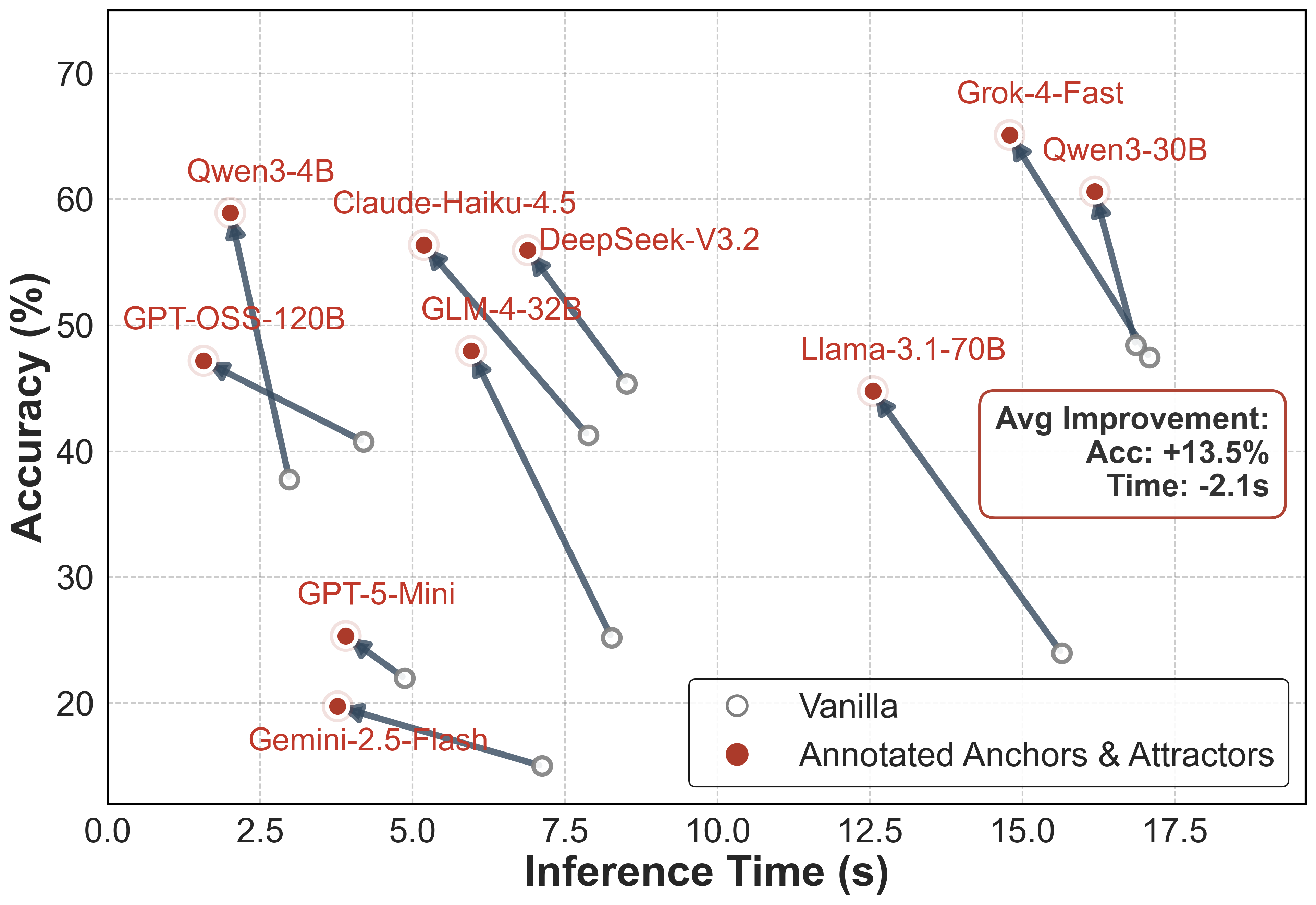
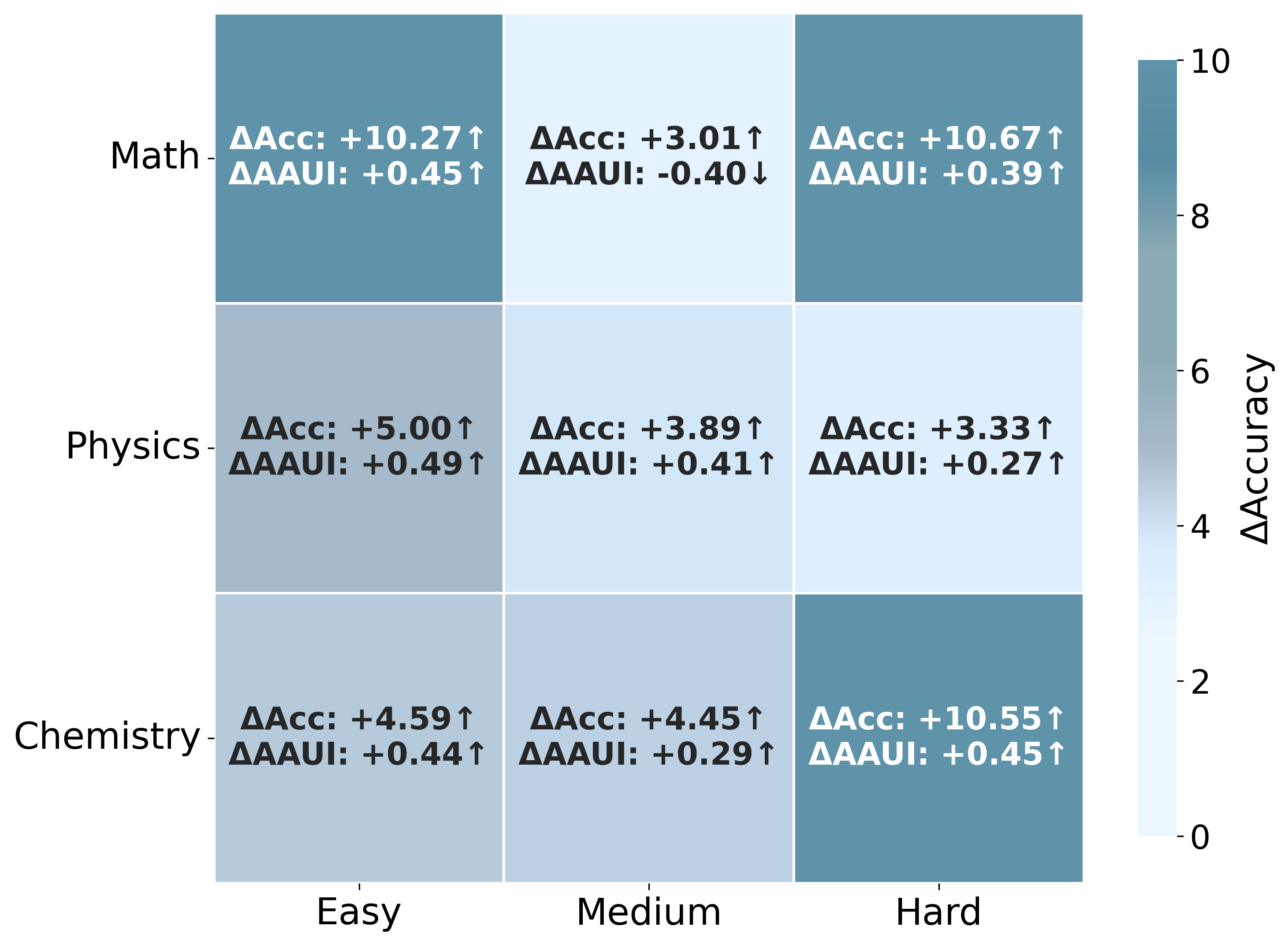
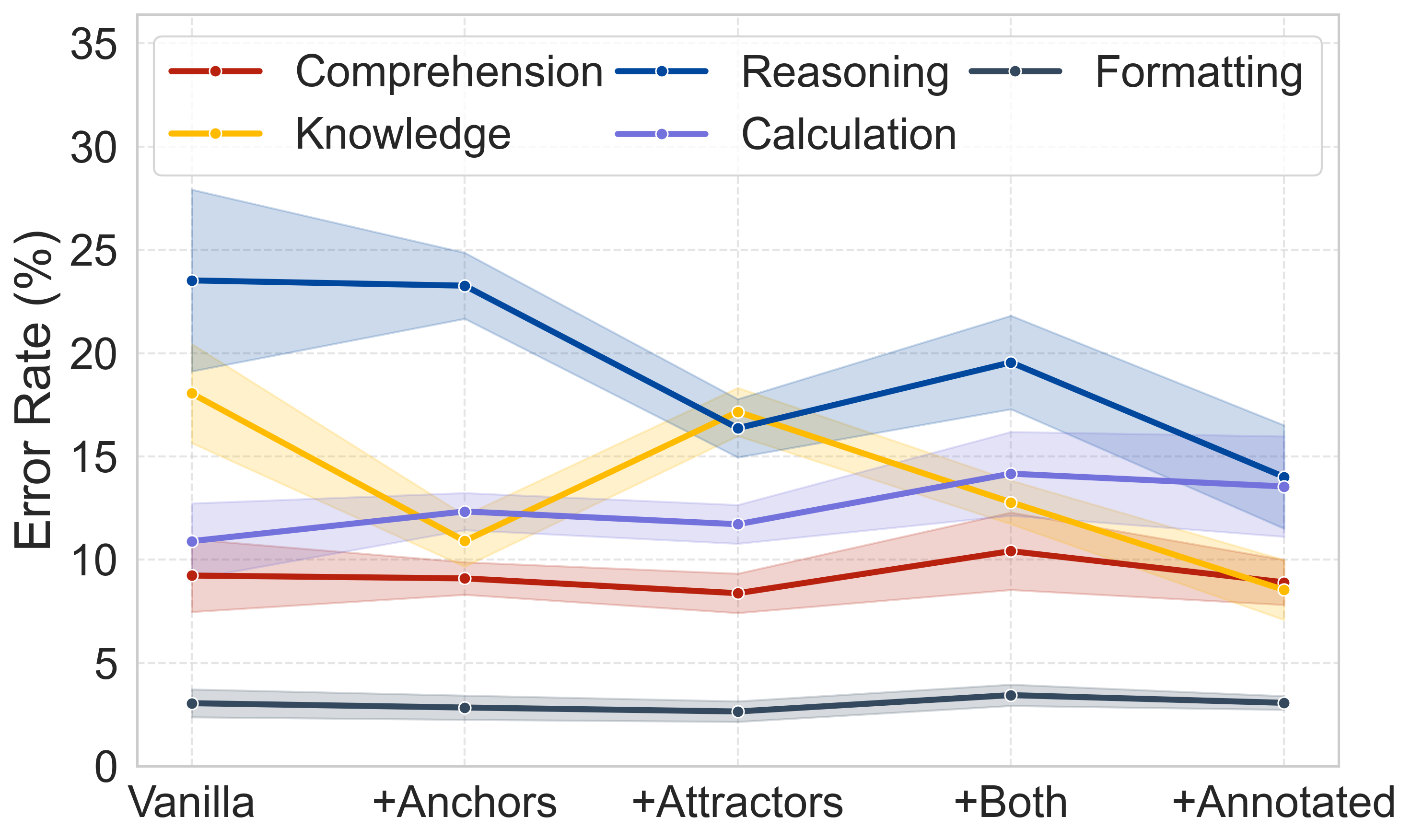
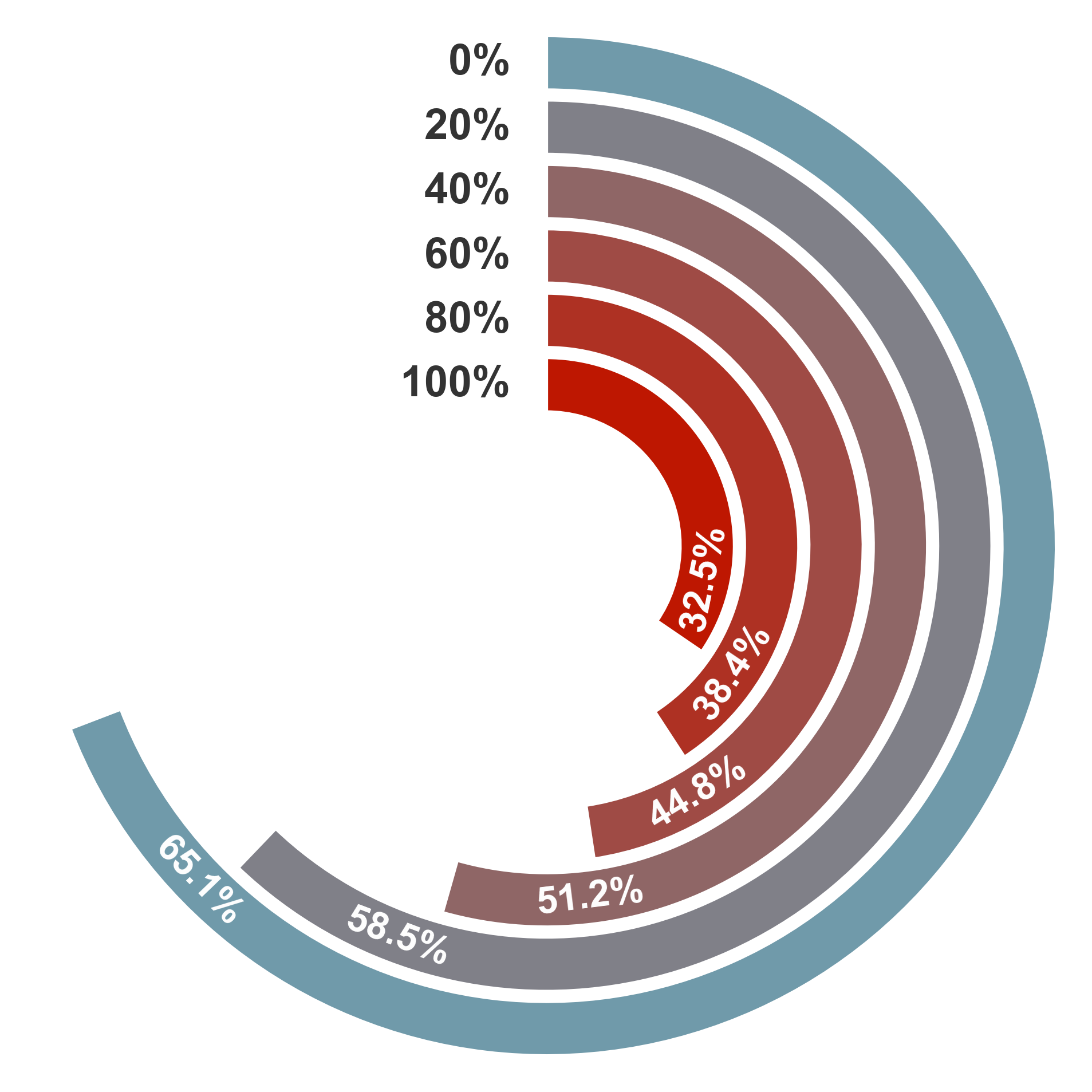
Performance comparison across three different memory paradigms.
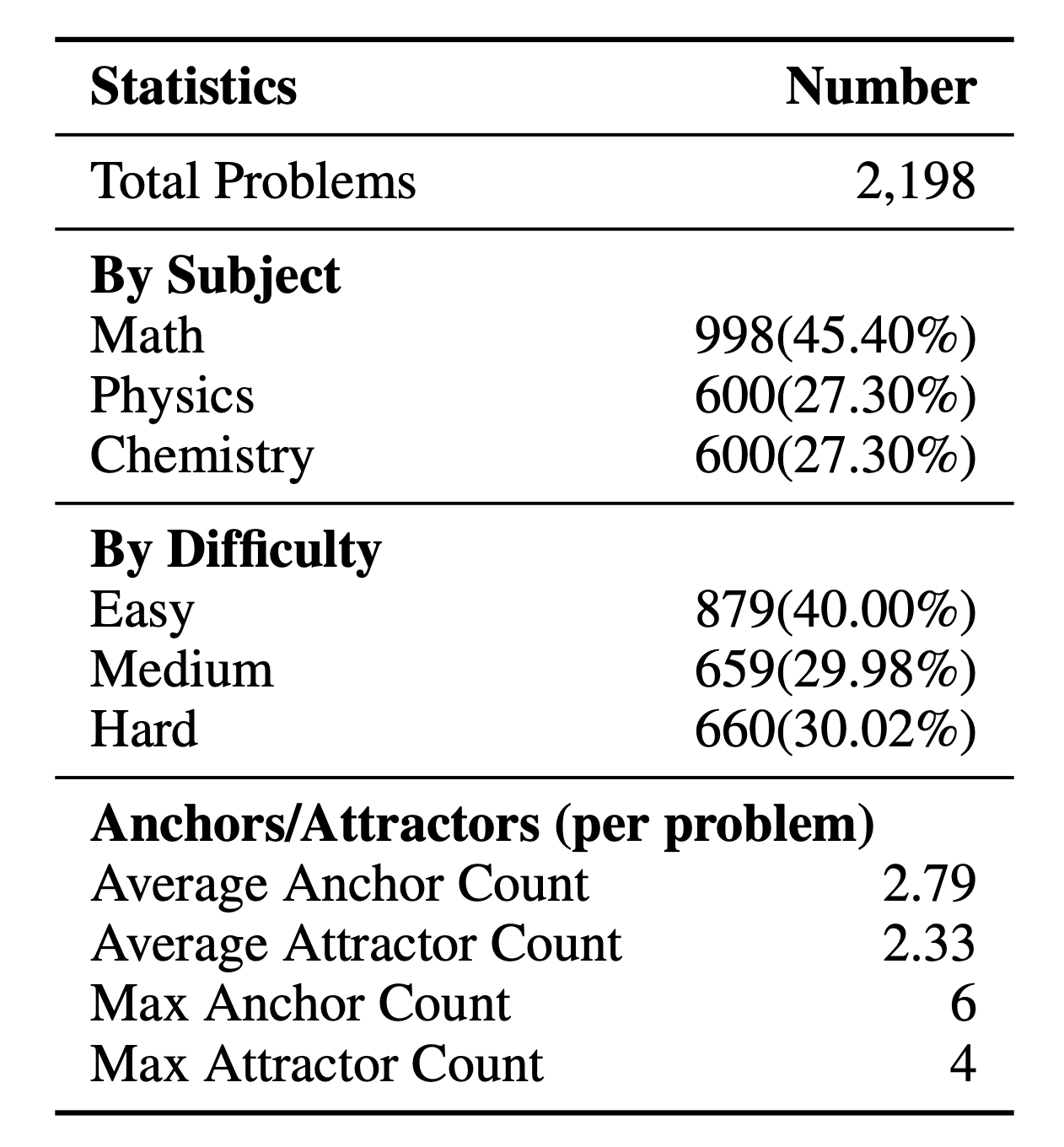
AAUI (Anchor-Attractor Utilization Index) measures the effective usage of memory.
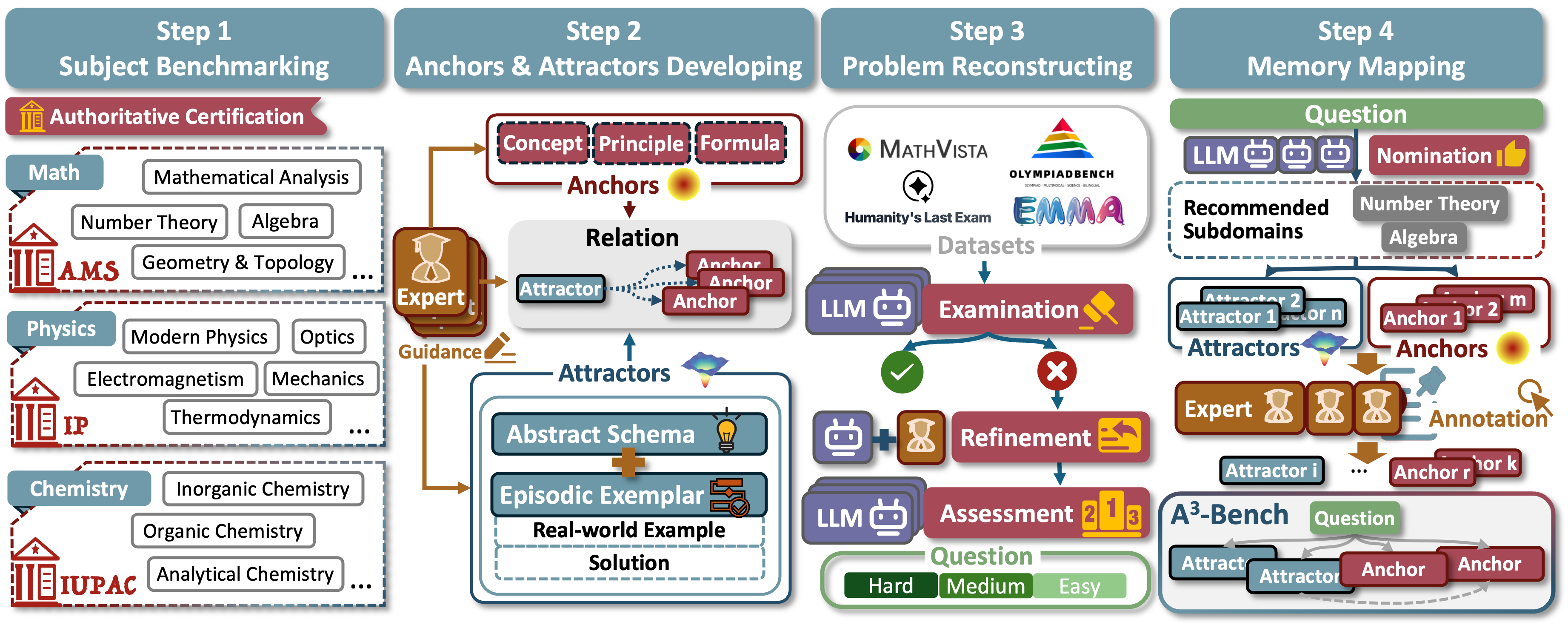
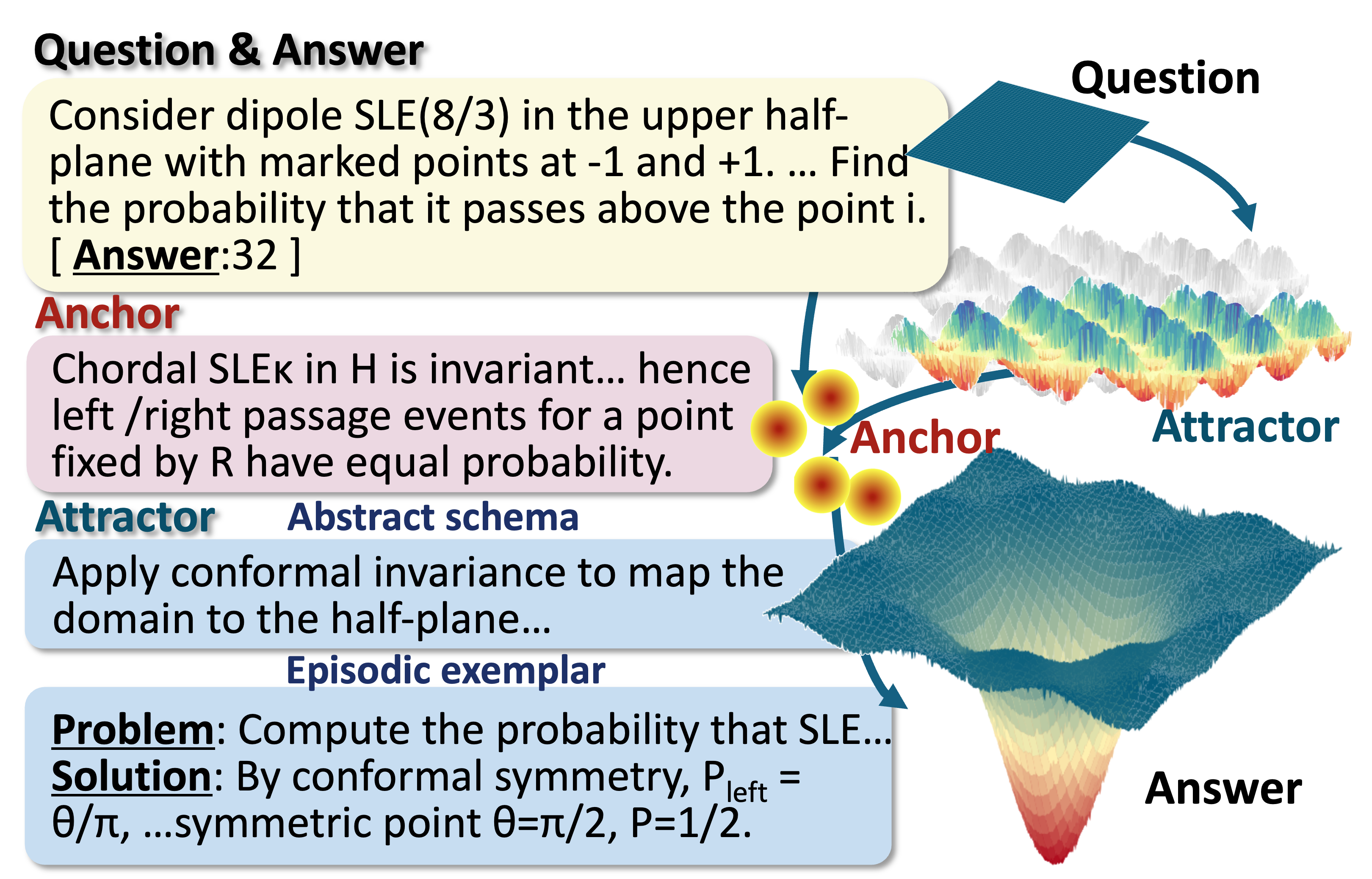
1. Annotated Anchors & Attractors
Models are provided with expert-annotated Anchors and Attractors. This represents the ideal memory utilization scenario.
| # | Model | Avg. Acc (%) | Math | Physics | Chemistry | AAUI | Tokens |
| 1 | Grok-4-Fast 🥇 | 65.10 | 75.94 | 60.12 | 78.75 | 0.97 | 2.64M |
| 2 | Qwen3-30B 🥈 | 60.60 | 73.18 | 67.08 | 71.67 | 0.95 | 2.73M |
| 3 | Qwen3-4B 🥉 | 58.92 | 72.18 | 61.52 | 69.17 | 0.92 | 2.68M |
| 4 | Claude-Haiku-4.5 | 56.37 | 70.93 | 56.21 | 74.58 | 0.77 | 2.26M |
| 5 | DeepSeek-V3.2 | 55.96 | 65.66 | 72.50 | 73.75 | 0.88 | 1.65M |
| 6 | GLM-4-32B | 47.95 | 63.91 | 55.83 | 55.42 | 0.92 | 1.62M |
| 7 | GPT-OSS-120B | 47.18 | 59.40 | 47.90 | 63.33 | 0.68 | 2.05M |
| 8 | Llama-3.1-70B | 44.77 | 56.64 | 45.83 | 55.00 | 0.96 | 1.69M |
| 9 | GPT-5-Mini | 25.34 | 36.59 | 32.57 | 22.92 | 0.74 | 2.33M |
| 10 | Gemini-2.5-Flash | 19.75 | 37.84 | 35.07 | 8.33 | 0.69 | 2.34M |
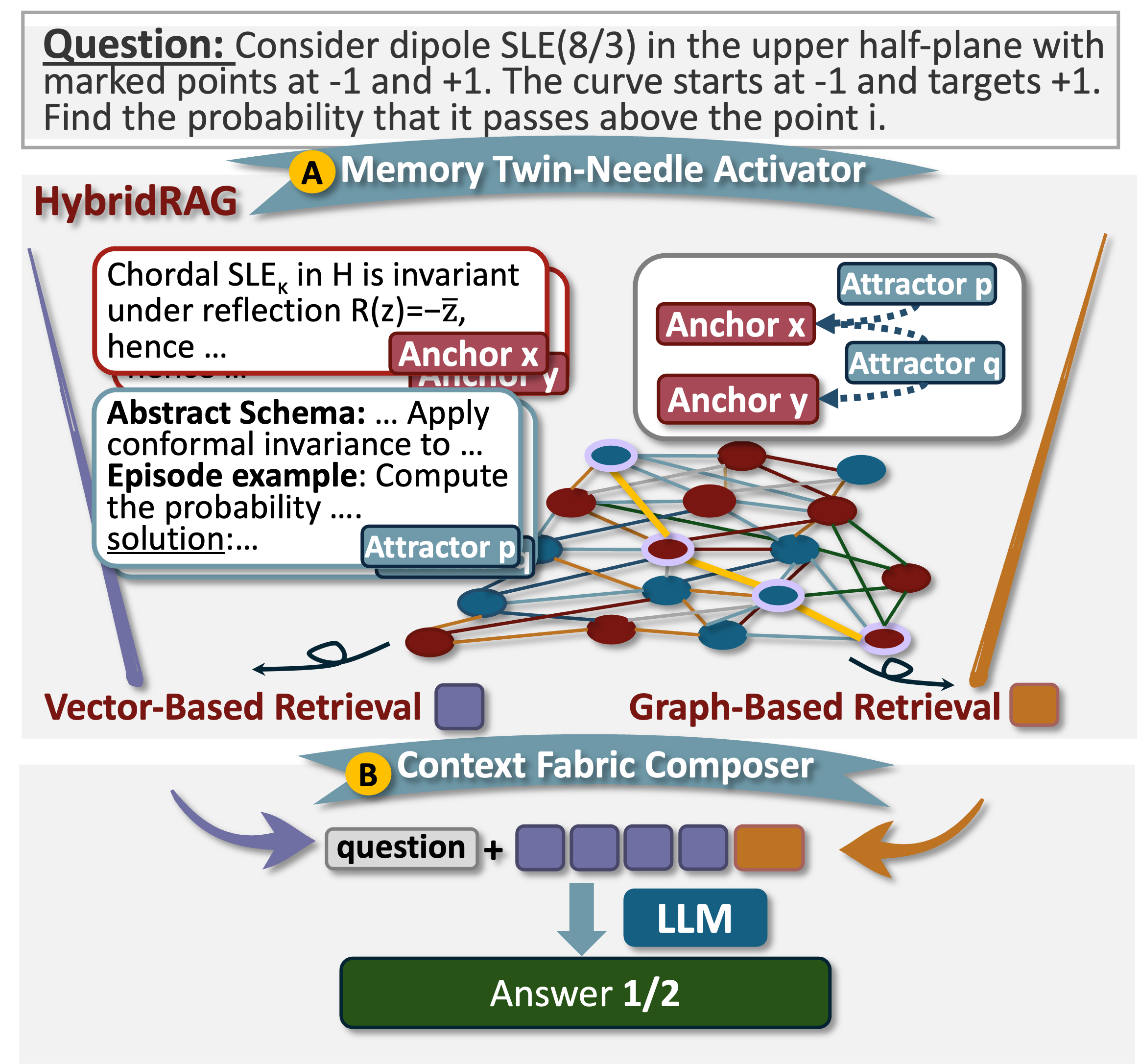
2. Retrieved Anchors & Attractors (HybridRAG)
Models retrieve memory automatically using HybridRAG. This evaluates the system's ability to find and use relevant knowledge.
| # | Model | Avg. Acc (%) | Math | Physics | Chemistry | AAUI | Tokens |
| 1 | Grok-4-Fast 🥇 | 56.69 | 68.92 | 72.50 | 65.00 | 0.66 | 3.17M |
| 2 | Claude-Haiku-4.5 🥈 | 51.18 | 64.66 | 60.42 | 62.50 | 0.46 | 2.58M |
| 3 | DeepSeek-V3.2 🥉 | 47.27 | 59.40 | 49.10 | 44.17 | 0.22 | 1.94M |
| 4 | GPT-OSS-120B | 47.22 | 56.14 | 57.08 | 52.08 | 0.44 | 2.48M |
| 5 | Qwen3-30B | 44.31 | 64.16 | 60.42 | 39.17 | 0.36 | 1.97M |
| 6 | GLM-4-32B | 39.40 | 59.90 | 52.50 | 29.58 | 0.41 | 1.82M |
| 7 | Qwen3-4B | 38.13 | 59.15 | 46.59 | 30.83 | 0.27 | 1.87M |
| 8 | Llama-3.1-70B | 28.98 | 44.11 | 37.47 | 20.83 | 0.33 | 1.88M |
| 9 | Gemini-2.5-Flash | 21.66 | 30.58 | 30.26 | 23.75 | 0.14 | 2.77M |
| 10 | GPT-5-Mini | 18.74 | 26.32 | 24.35 | 18.33 | 0.09 | 2.74M |
3. Vanilla (No Memory)
Standard zero-shot inference without external memory augmentation.
| # | Model | Avg. Acc (%) | Math | Physics | Chemistry | Tokens |
| 1 | Qwen3-30B 🥇 | 48.41 | 55.64 | 48.90 | 60.83 | 1.81M |
| 2 | Grok-4-Fast 🥈 | 47.45 | 51.38 | 43.99 | 58.75 | 1.18M |
| 3 | DeepSeek-V3.2 🥉 | 45.36 | 46.37 | 38.28 | 60.42 | 0.70M |
| 4 | Claude-Haiku-4.5 | 41.26 | 43.11 | 50.42 | 64.58 | 0.96M |
| 5 | GPT-OSS-120B | 40.76 | 49.12 | 40.18 | 50.42 | 0.44M |
| 6 | Qwen3-4B | 37.76 | 47.62 | 42.89 | 46.67 | 1.91M |
| 7 | GLM-4-32B | 25.20 | 37.59 | 28.56 | 30.00 | 0.44M |
| 8 | Llama-3.1-70B | 23.96 | 34.21 | 26.94 | 28.21 | 0.57M |
| 9 | GPT-5-Mini | 21.97 | 31.83 | 26.65 | 26.67 | 1.35M |
| 10 | Gemini-2.5-Flash | 15.01 | 24.81 | 26.15 | 5.00 | 1.30M |